|
|

|

|
| e-Pub |
Section: New Results
Bayesian Perception
Participants : Christian Laugier, Lukas Rummelhard, Amaury Nègre, Jean-Alix David, Procópio Silveira-Stein, Jerome Lussereau, Tiana Rakotovao, Nicolas Turro (sed), Jean-François Cuniberto (sed), Diego Puschini (cea Dacle), Julien Mottin (cea Dacle).
Conditional Monte Carlo Dense Occupancy Tracker (CMCDOT)
Participants : Lukas Rummelhard, Amaury Nègre, Christian Laugier.
In 2015, the research work on Bayesian Perception has been done as a continuation and an extension of some previous research results obtained in the scope of the former Inria team-project e-Motion. This work exploits the Bayesian Occupancy Filter (BOF) paradigm [28] , developed and patented by the team several years ago (The Bayesian programming formalism developed in e-Motion, pioneered (together with the contemporary work of Thrun, Burgards and Fox [53] ) a systematic effort to formalize robotics problems under Probability theory –an approach that is now pervasive in Robotics.). It also extends the more recent concept of Hybrid Sampling BOF(HSBOF) [46] , whose purpose was to adapt the concept to highly dynamic scenes and to analyse the scene through a static-dynamic duality. In this new approach, the static part is represented using an occupancy grid structure, and the dynamic part (motion field) is modeled using moving particles. The HSBOF software has been implemented and tested on our experimental platforms (equipped Toyota Lexus and Renault Zoe) in 2014 and 2015; it has also been implemented in 2015 on the experimental autonomous car of Toyota Motor Europe in Brussels.
The objective of the research work performed in 2015 was to overcome some of the shortcomings of the HSBOF approach (In the current implementation of the HSBOF algorithm, many particles are still allocated to irrelevant areas, since no specific representation models are associated to dataless areas. Moreover, if the filtered low level representation can directly be used for various applications (for example mapping process, short-term collision risk assessment [31] , [48] , etc), the retrospective object level analysis by dynamic grid segmentation can be computationally expensive and subjected to some data association errors.) , and to obtain a better understanding of the observed dynamic scenes through the introduction an additional object level into the model. The new framework, whose development will be continued in 2016, is called Conditional Monte Carlo Dense Occupancy Tracker (CMCDOT) [10] . This work has mainly been performed in the scope of the project Perfect of IRT Nanoelec (Nanoelec Technological Research Institute (Institut de Recherche Technologique Nanoelec)) (financially supported by the French ANR agency (National Research Agency (Agence Nationale de la recherche))), and also used in the scope of our long-term collaboration with Toyota.
The CMCDOT approach introduces an drastic change in the underlying formal expressions: instead of directly filtering the occupancy data, we have added hidden states for representing what is currently present in a cell. Then, the occupancy distribution can then be inferred from those hidden states. Besides presenting a clear distinction between static and dynamic parts, the main interest of this new approach is to introduce a specific processing of dataless areas, excluding them from the velocity estimation (and consequently optimizing the processing of the dynamic parts) and disabling their temporal persistence (which is used to generate estimation bias in newly discovered areas). This updated formalism also enables the introduction of an appropriate formal model for the particle initialization and management (which was previously more isolated).
Another important added feature is the automatic segmentation of the dynamic parts of the occupancy grid, according to its shapes and dynamics. While the CMCDOT tracks spatial occupancy in the scene without object segmentation, Detection and Tracking of Moving Objects (DATMO) is often required for high level processing. A standard approach would be to analyse the CMCDOT outputs, to apply a clustering algorithm on the occupancy grid (enhanced by velocities), and to use those clusters as potential object level targets. This clustering can turn out to be computationally expensive, considering the grid dimensions and the size and complexity of the dynamic particle model. The basic idea of our new approach is to exploit the particle propagation process within the CMCDOT: the way particles are resampled can leads to the wanted segmentation after a number of time steps. After initialization, at each step, the particles that correctly fit the motion of a dynamic object are multiplied, those which do not are forgotten. In a few steps, the best particles propagate in the object, and the object motion is fully described by a set of particles deriving from a common particle root. By marking each particle at the initialization step with a unique identification number, all the dynamic areas which are coherent in term of space and motion are marked after few iterations. The convergence of those markers is fastened by additional rules.
|
|





Experimental results showed that the insertion of an "unknown" state in the model leads to a better distribution of dynamic samples on observed areas (see figure 2 ) and also allows us to be more reactive and accurate on the velocity distributions, while requiring less computing power (see figure 3 ).
The intrinsic clustering approach has also been tested on real road data, showing promising results in real-time tracking of moving objects, regardless of their type. The method could be improved by managing split-and-merge events that can occur in complex urban environment (see figure 4 ).
|


Multimodal dynamic objects classification
Participants : Amaury Nègre, Jean-Alix David.
The method described in section 7.2.1 allows to obtain a list of dynamic objects and to track each object over time. In order to increase the level of representation of the environment, we have developed a method to classify detected objects using both the camera images and the occupancy grid representation estimated by the CMCDOT. For each detected object, the bounding box of the object is projected in the camera image and a local image is extracted from the camera. Jointly, we can extract a patch from the occupancy grid around the dynamic object position. The extracted camera image and the occupancy grid patch can then be used as the input of a Deep Neural Network (DNN) to identify the class of the object. The DNN we designed is a combination on two classic neural networks, the "ImageNet" Convolutional Neural Networks [35] for the camera image input and the "LeNet" [37] for the occupancy grid input (see fig 5 ).

To train and evaluate the model, a dataset has been created from the data recorded with the Lexus platform. We extracted the camera images and the occupancy grid for each object detected by the CMCDOT module, then we manually annotated the object class among "pedestrian", "crowd", "car", "truck", "two-wheelers" and "misc" categories. The resulting dataset contains more than 100000 camera images & occupancy grid pairs. The training process and the classification module has been done by using the open source library caffe [33] . An example of the obtained results is shown on fig 6 . The percentage of good classification is greater than 90% on our evaluation dataset.

Visual Map-Based Localisation with OSM
Participants : Jean-Alix David, Amaury Nègre.
This module aims to improve both the global localization provided by the GPS (Global Positioning System) and the lane-relative localization information estimated by a lane tracker by combining their mutual strengths. The idea is to detect lane markings on the road using a camera, and then to compare the extracted lines with those stored in the map. This is done using the ICP (Iterative Closest Point) algorithm. This work is described in a confidential Toyota project report entitled Real Traffic Data Acquisition and Risk Assessment Experiments.
The map
Our solution is based on a post-processed OSM (OpenStreetMap) map shown on figure 7 . Typically, these maps contain information on the roads and lanes, but contain no information about lane markers on the ground. Thus, we ran a semi-manual process to complete the existing maps with information about the number and type of markers.
New data are stocked in a local server. Requests can be sent to this server to fetch map data using HTTP protocol.
|
Line detection
The line extraction is done using ridge detection on a top-down view of the camera image. Only one monocular camera is used, as it is an inexpensive sensor, and needs only to be calibrated once. The line detection is based on an algorithm using Laplacian to extract ridges of the monochrome image. The algorithm is implemented for parallelized calculation using CUDA on a GPU, for an improved performance. Figure 8 shows the results of the ridge detector.
|




ICP-based line matching
The extracted lines are matched and aligned with the map using the ICP algorithm to improve the localization of the vehicle. The ICP algorithm iteratively minimizes the total alignment error between the points detected as ridges and the segments of line extracted from the map. Finally, figure 8 .d shows how the algorithm can correct the vehicle localization. The algorithm is able to accurately track the orientation and position. However, the lateral displacement may be off by a multiple of the lane width, depending on how the algorithm has been initialized. In practice, this effect is often mitigated due to the existence of single-lane roads such as highway entrances.
The results are very promising on highways, but the algorithm has a lower performance on other types of roads, mostly due to irregularities.
Integration of Bayesian Perception System on Embedded Platforms
Participants : Tiana Rakotovao, Christian Laugier, Diego Puschini(cea Dacle), Julien Mottin(cea Dacle).
Safe autonomous vehicles will emerge when comprehensive perception systems will be successfully integrated into vehicles. However, our Bayesian Perception approach requires high computational loads that are not supported by the embedded architectures currently used in standard automotive ECUs.
To address this issue, we first explored new embedded hardware architecture credible for the integration of OGs (Occupancy Grids) into autonomous vehicles [19] . We studied in particular recent emerging many-core architectures, which offer higher computing performance while drastically reducing the required power consumption (typically less than 1W). In such architectures, the computation of OGs can be divided into several independent tasks, executed simultaneously on separated processing core of a many-core.
Experiments were conducted on data collected from urban traffic scenario, produced by 8 LIDAR layers mounted on the Inria-Toyota experimental Lexus vehicle. These experiments demonstrate that the many-core produces OGs largely in real-time: 6 time faster than the sensor reading rate.
Besides, we also proposed a mathematical improvement of the OG model, for performing multi-sensor fusion more efficiently than the standard approach presented in [29] . In our approach, the fusion of occupancy probabilities requires fewer operations. This model improvement makes it possible the implementation of OG-based multi-sensor fusion on simple hardware architectures. This perspective applies to microcontroller, ASICs or FPGAs which are more and more present in computing platforms recently present on the automotive market.
Experimental Vehicle Renault ZOE
Participants : Nicolas Turro (sed), Jean-François Cuniberto (sed), Procópio Silveira-Stein, Amaury Nègre, Lukas Rummelhard, Jean-Alix David, Christian Laugier.
Experimental Vehicle Renault ZOE
In the scope of the Perfect projet of the IRT nanoelec, we have started to develop in 2014, an experimental platform based on an equipped Renault Zoe. The development of this platform has been pursed in 2015.
The vehicle has been enhanced with a tablet to display the new HMI (Human Machine Interface), figure 9 (a) illustrates. The HMI displays the detected dynamic objects over the camera image and the graph of collision risk at different time horizon.
|
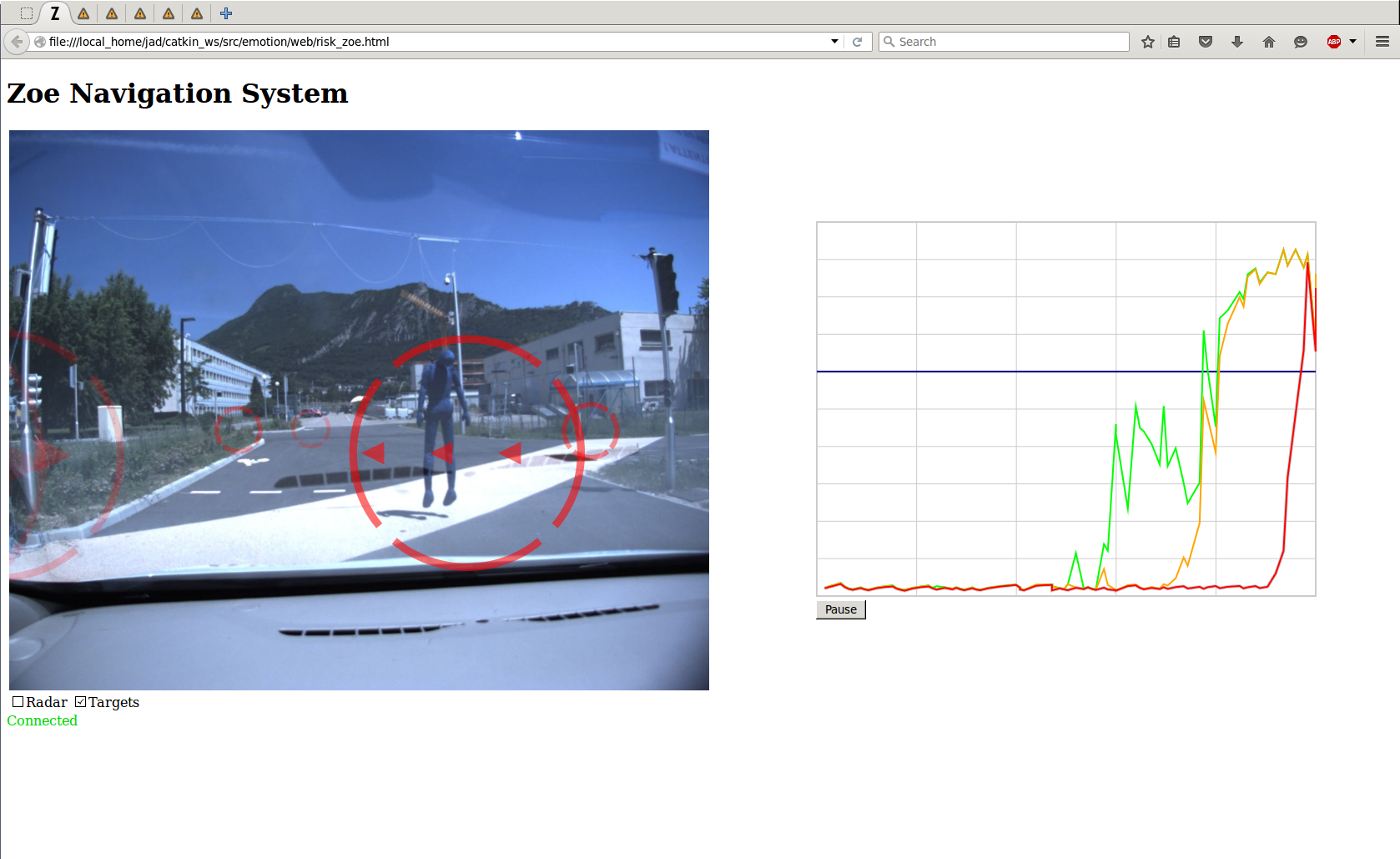


New experiments have also been designed to test the perception algorithms and the recent implementation of the collision risk alert. These experiments simulate collisions with people using a fabric mannequin, as shown on figure 9 (b), and an inflatable ball.
Finally, we have also developed two movable devices in order to enhance V2X (Vehicle-to-Vehicle and Vehicle-to-Infrastructure) communication experiments (see figure 9 (c)):
-
A movable communicating cone equipped with a GPS and a V2X communication box, which broadcast its position to near V2X listeners.
-
A movable smartbox equipped with a GPS, a V2X communication box, a LIDAR sensor and a Nvidia Tegra K1 board. The CMCDOT algorithm is implemented on it, and the detected objects are broadcasted to other communicating devices. The smartbox can be mounted on another vehicle or be placed as part of a static infrastructure. Both are alimented by batteries and aim at minimizing their energy consumption.